Assessing the Credibility of the O*NET Database: Creating a Crosswalk with ESCO Data Using Vectorization Methods
Understanding the O*NET ESCO Data Crosswalk: A Comprehensive Overview
The O*NET ESCO Data Crosswalk is a vital tool in the intersection of occupational data and skills mapping. This article provides a thorough examination of the O*NET ESCO Data Crosswalk, its significance, and practical applications in workforce development.
What is O*NET?
O*NET, the Occupational Information Network, is a comprehensive database that categorizes and describes various occupations in the United States. Managed by the U.S. Department of Labor, O*NET provides detailed information about job roles, including required skills, necessary training, and employment statistics.
What is ESCO?
The European Skills, Competences, Qualifications and Occupations (ESCO) framework serves a similar purpose in Europe. ESCO aims to create a common language for skills and occupations across EU countries, facilitating better communication within the labor market, education, and training sectors.
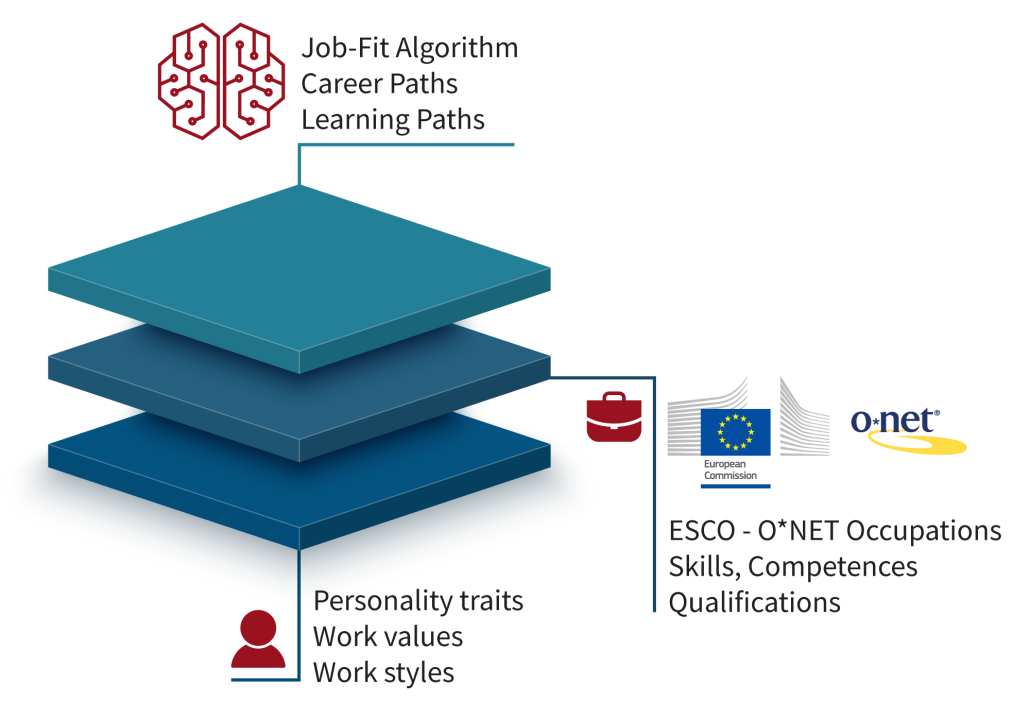
The O*NET ESCO Data Crosswalk Explained
The O*NET ESCO Data Crosswalk serves as a bridging tool that maps O*NET occupational codes to ESCO classifications. This crosswalk enhances understanding between the two systems and provides several benefits:
- Harmonization of Data: It allows for the integration of occupational data between the U.S. and European markets, which is essential for multinational companies and organizations.
- Improved Career Pathways: By understanding how jobs relate across different systems, individuals can better navigate their career paths, seeking opportunities that match their skills and qualifications.
- Enhanced Workforce Development: Educational programs can align more closely with labor market demands, ensuring that training initiatives are relevant and effective.
Importance of the O*NET ESCO Data Crosswalk
Understanding the O*NET ESCO Data Crosswalk is crucial for several reasons:
- Global Workforce Integration: As businesses become increasingly global, having a common understanding of occupational classifications can help organizations identify talent across borders.
- Skill Matching: The crosswalk facilitates the alignment of educational offerings with labor market needs, ensuring that job seekers have the necessary skills to access emerging opportunities.
- Policy Development: Policymakers can utilize this data to craft informed workforce development strategies that consider both domestic and international markets.
Applications of the O*NET ESCO Data Crosswalk
The O*NET ESCO Data Crosswalk has several practical applications, including:
- Career Development Services: Career counselors can use the crosswalk to provide clients with more informed guidance on job opportunities and necessary qualifications.
- Labor Market Analysis: Researchers and analysts can utilize the crosswalk to study employment trends and workforce dynamics effectively.
- Employer Insights: Companies can leverage the crosswalk to better understand skill requirements for various roles, enhancing their recruitment strategies.
Conclusion
The O*NET ESCO Data Crosswalk is an essential tool for bridging the gap between occupational data systems in the U.S. and Europe. By improving communication about skills and job roles, the crosswalk plays a vital role in career development and workforce planning. Understanding this data crosswalk can greatly aid job seekers, employers, and educators in navigating today’s competitive job market.

